芯城品牌采购网 > 品牌资讯 > 技术方案 > 助AI实现边缘计算的理想之选-FPGA






助AI实现边缘计算的理想之选-FPGA
芯城品牌采购网
26448
人类大脑之中有将近 1000亿个神经元。虽然这是一个天文数字,但将这些神经元组织成网络的神经相连的数量是数万亿的数量级,而神经相连的数量明显影响大脑的能力。FPGA外部的互连性相似于人脑中的神经连接。FPGA中的可编程逻辑结构也以相似的方式互联,这就是为什么英特尔® FPGA是神经网络和其他人工智能工作负载构建的完美选择。在逻辑和线互连的层面之上,FPGA的位级动态可编程性就像一个敏捷的大脑,可变更注意力,将注意力分散在手头的具体任务之上。此外,FPGA的内部I/O在历史上还获取了其他硬件架构所没的杰出灵活性,能相连到各种来源的传感器,如雷达、音频、振荡和视觉。这些功能允许信号实时流向和流入FPGA,构建了与人脑相当的高阶智能水平。
英特尔®FPGA芯片系列包含英特尔 Cyclone®}10 GX FPGA、英特尔Arria®}10 GX FPGA和英特尔Stratix®}10 GX FPGA等。这些产品具备I/O灵活性、高功耗(或每个推理的能耗)和高延迟,可在人工智能推理方面造成优势。这些优势获得了英特尔® FPGA和片之上系统(SoC)系列产品的补充,从而进一步明显提升了人工智能推理性能。这三个家族分别是英特尔® Stratix®}10 NX FPGA和英特尔®}Agilex的全新成员™FPGA家族:英特尔® Agilex™D系列FPGA,以及全新的英特尔{4安捷力{5} ® Agilex™设备家族。这些英特尔® FPGA和SoC系列包含专门针对张量数学运算展开优化的DSP模块,为加快人工智能计算打下了基础。
首款使用张量块的英特尔® FPGA是2020年6月18日发行的英特尔Stratix®10 NX FPGA。英特尔® Stratix® 10 NX FPGA的张量块架构针对人工智能测量之中常见的矩阵-矩阵或矢量-矩阵乘法和加法乘法展开了改进,并可精确用作各种大小的矩阵。张量模块拥护INT8和INT4数据测量,并通过共享指数拥护FP16和FP12块浮点数格式。
上一个英特尔® Agilex™器件家族搭载了可变精度数字信号处置( DSP)模块,可获取各种人工智能功能,并结合在全新的英特尔® Agilex™FPGA和SoC FPGA结构在后面的块设计师的基础之上,DSP块还讲解了英特尔®}Stratix®}10 NX FPGA之中采用的张量块的各种功能。具有AI张量块的增强DSP引进了两个全新的关键操作:AI的张量处理能力和信号处置运用中的复数拥护。这些应用包含快速傅立叶转换(FFT)和简单的庞大脉冲响应(FIR)滤波器等。
第一个模式减弱AI与INT8张量模式。这种模式获取20个INT 8乘法在一个减弱的DSP与AI张量块。与以前的英特尔®}相对,INT8的计算密度提升了5倍阿基利克斯™设备系列。张量模式使用两列张量结构,同时具备INT32和FP32级联和累加功能,还拥护块浮点索引,以提升推理精度和高精度培训。此外,可变精度DSP的人工智能能力也获得了减弱。矢量模式也从四个INT9乘数(乘数)降级到六个INT9乘数。这些模式对于以人工智能为中心的张量数学运算和各种 DSP芯片应用特别常用。

AI和DSP计算密度的数量级提升。
仅局限于英特尔®阿基利克斯™D系列FPGA和全新的英特尔® Agilex™代号为圣丹斯·梅萨的设备家族
第二种全新模式是简单乘法,它在行驶简单乘法时使张量模块的性能提升一倍。在过往,复数乘法需两个DSP块,但这款全新的英特尔® Agilex™FPGA和SoC FPGA系列可在单个增强型DSP之上采用AI张量块构建16位定点复数乘法乘法。
分布式人工智能/机器学习边缘克服方案通常非常复杂且难以研发。英特尔获取的开发工具和软件可增进开放标准并拥护容器化和云原生研发,协助开发人员修改工作流程并加速分布式边缘克服方案的部署。对于采用英特尔® FPGA和SoC开发人工智能/机器研习应用程序的用户,英特尔获取开发工具:。
英特尔® oneAPI AI Analytics Toolkit(AI Suite)为数据科学家、AI开发人员和研究人员获取了一套熟知的Python工具和框架,以加快端到端数据科学和分析管道。通过该工具套件,英特尔获取了一个oneAPI库,该库拥护高级别测量改进,以最大限度地提升从预处理到机器学习等各种工作负载的性能,并为高效的模型开发获取互操作性。
英特尔®}Python分发版拥护盛行的库和框架,如TensorFlow、Keras、PyTorch、oneDNN和BigDL,可用作在多个英特尔®}测量平台之上设立高速机器学习应用。这些工具拥护针对普遍的AI/ML工作负载展开快速应用程序研发。
OpenVINO的英特尔®发售版™Toolkit拥护对边缘计算机视觉用例至关重要的深度研习应用程序的开发。
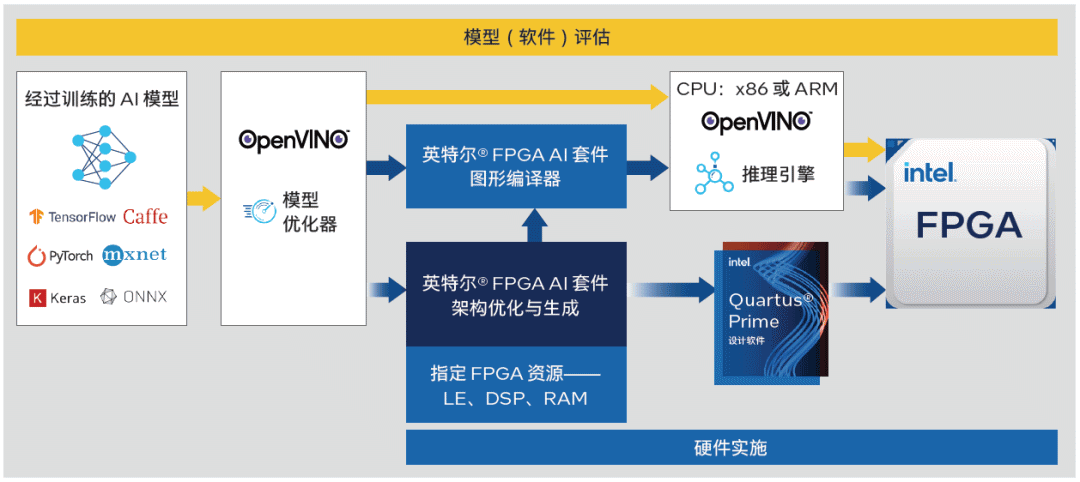
英特尔® FPGA AI Kit使FPGA设计人员、机器学习工程师和软件开发人员能有效地改进基于英特尔®}FPGA的AI设计。透过常用和主流行业框架,如TensorFlow、PyTorch和OpenVINO™Toolkit,英特尔® FPGA AI Suite中的实用程序加速了基于FPGA的AI推理的开发,同时还充分利用了英特尔® Quartus{3 Prime Software强劲而成熟期的FPGA开发流程。
英特尔® FPGA AI Kit非常灵活,可针对各种系统级用例展开配置。通过一键手动,用户可分解改进的AI推理IP块,并将其结合到英特尔® Quartus® Prime软件之中。用户还可在英特尔FPGA AI套件之中为架构优化器指定设备资源(DSP、内存、逻辑单元)和吞吐量。这种独有的定制功能对于探险嵌入式AI应用的尺寸、重量和功耗等设计和改进尺寸至关重要。
您可通过下列四种方式透过英特尔获取的开发工具将英特尔FPGA和人工智能/机器研习结合到您的系统之中:
1. 采用基于FPGA的AI/机器研习加速器构建CPU卸载。主机CPU通过PCIe接口与AI/机器研习加速器通信。INTEL FPGA间接拥护PCIe与主机的INTEL CPU相连。
2. 使用INTEL FPGA构建AI加速器和附加逻辑,构建多功能CPU卸载。 INTEL FPGA为主机的INTEL CPU获取AI/机器研习加快,并构建应用程序所需的任何附加逻辑。如在实行例1中,主机CPU通过PCIe接口与AI/ML加速器通讯。
3. 提炼/在线处理+人工智能。基于FPGA的人工智能加速器间接摄入数据,采用人工智能和算法工作负载对其展开处理,然后通过PCIe相连将处置之后的数据和推测传送到主机的INTEL CPU。
4. INTEL SoC FPGA使用集成CPU(ARM或Nios®处理器核心)当作人工智能/机器学习加速器,间接提炼和处理数据,构建人工智能和机器研习逻辑,然后将处置之后的数据连接起来,逻辑被传送到云端。FPGA还专责构建应用程序所需的任何附加逻辑。
免责声明:
文章内容转自互联网,不代表本站赞同其观点;
如涉及内容、图片、版权等问题,请联系2644303206@qq.com我们将在第一时间删除内容!